- HA(High Availability)구성을 위한 zookeeper 설치
1. zookeeper를 사용할 노드에 zookeeper user 생성
2. namenode(nn01)에서 wget을 통하여 zookeeper 설치
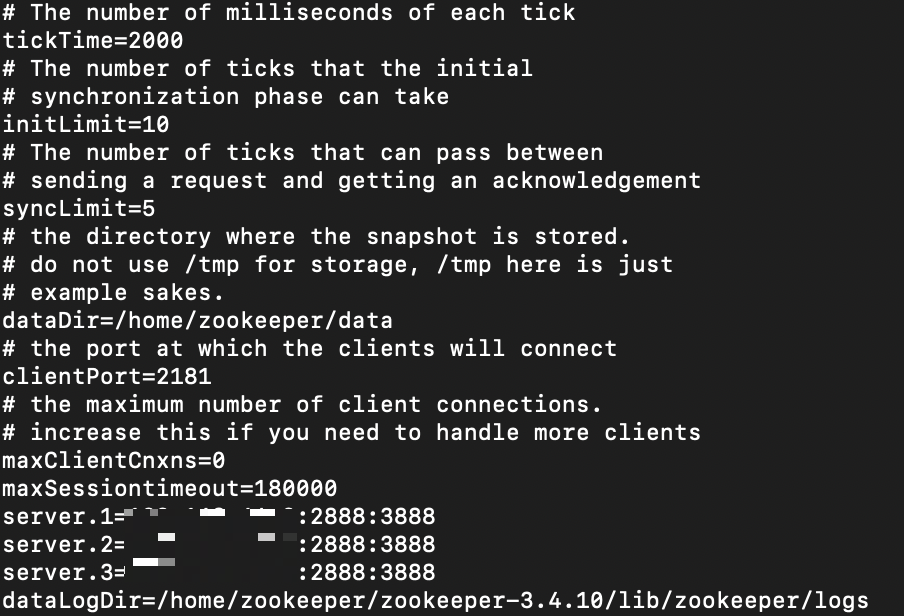
3. conf/zoo_sample.cfg의 파일을 conf/zoo.cfg파일로 복사하여 zoo.cfg의 파일을 수정
4. 수정된 zoo.cfg파일을 포함하여 새롭게 zookeeper파일 압축하여 다른 zookeeper 노드들에 배포
5. 배포된 노드들에서 zookeeper파일을 압축해제
6. zookeeper 사용 노드들에 myid 지정(nn01은 1, rm01은 2, jn01은 3으로 지정하였습니다.)
7. zookeeper설치 폴더/bin/zkServer.sh start 명렁어를 각 zookeeper 노드들에서 실행
-> 만약 zookeeper 노드가 총 3대라면 follower mode2대, leader mode 1대의 비율이 되야합니다.
8. zookeeper 종료는 zookeeper설치 폴더/bin/zkServer.sh stop 명령어를 통해 모두 종료
zookeeper 실행시
Error contacting service. It is probably not running 에러가 발생하였습니다.
위 에러 해결방법은 https://colly.tistory.com/15 작성하였습니다.
- Hadoop 설치
1. 모든 node에 hadoop user 생성
2. namenode(nn01)에서 wget을 통하여 hadoop 설치
3. core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml, hadoop-env.sh(java_home환경변수 설정, hadoop pid 설정) 수정 후 재압축 하여 모든 노드에 배포
4. 모든 서버에 /etc/profile.d/hadoop.sh 파일에서 hadoop_home, path 설정 후 생성
-zookeeper , hadoop 실행 순서
1. 주키퍼 장애 컨트롤러(zk) 초기화
hadoop설치 폴더/bin/hdfs zkfc -formatZK (최초 실행시 1번만 실행 / namenode에서 실행 - nn01)
2. 저널노드 실행
hadoop설치 폴더/bin/hdfs --daemon start journalnode(각각의 저널노드에서 실행 - nn01)
3. 네임노드(namenode) 초기화
hadoop설치 폴더/bin/hdfs namenode -format (최초 실행시 1번만 실행 / namenode에서 실행 - nn01)
4. 액티브 네임노드(active namenode)실행
hadoop설치 폴더/bin/hdfs --daemon start namenode(namenode에서 실행 - nn01 )
5. 액티브 네임노드용 주키퍼 장애 컨트롤러(zkfc)를 실행
hadoop설치 폴더/bin/hdfs --daemon start zkfc(namenode에서 실행 - nn01)
6. 데이터 노드 실행
hadoop설치 폴더/sbin/hadoop-daemons.sh start datanode(namenode에서 실행 - nn01)
7. 스탠바이 네임 노드 포맷, 액티브 네임노드의 메타 데이터를 스탠바이 네임노드로 복사
hadoop설치 폴더/bin/hdfs namenode -bootstrapStandby(stanbynamenode에서 실행 - rm01)
8. 스탠바이 네임노드 실행
hadoop설치 폴더/bin/hdfs --daemon start namenode(standbynamenode에서 실행 - rm01)
9. 스탠바이 네임노드에서 주키퍼 장애 컨트롤러 실행
hadoop설치 폴더/bin/hdfs --daemon start zkfc(standbynamenode에서 실행 - rm01)
10. yarn클러스터 실행
hadoop설치 폴더/sbin/start-yarn.sh(rm01에서 실행)
11. 액티브 - 스탠바이 네임노드 확인
hadoop 설치 폴더/bin/hdfs haadmon -getServiceState nn01 (active로 표시되야함)
hadoop 설치 폴더/bin/hdfs haadmon -getServiceState rm01 (standby로 표시되야함)
12. 각 서버별 실행된 파일 확인
jps로 확인