- 개념
디지털 환경에서 전체 실사용자를 대상으로 대조군(Control Group)과 실험군(Experimental Group)으로 나누어서 어떤 특정한 UI나 알고리즘의 효과를 비교하는 방법론입니다.
- 필요성
상관관계로부터 인과관계를 찾기위해, 정확히 이야기하면 인과관계일 가능성이 높은것을 찾아내기 위함입니다.
그래야 "원인"에 해당하는 요소에 개입을 하여 "결과"에 해당하는 요소가 우리가 원하는 방향으로 변화되도록 할 수 있습니다.
- A/B 테스트에서 사용자를 분리하는 방법
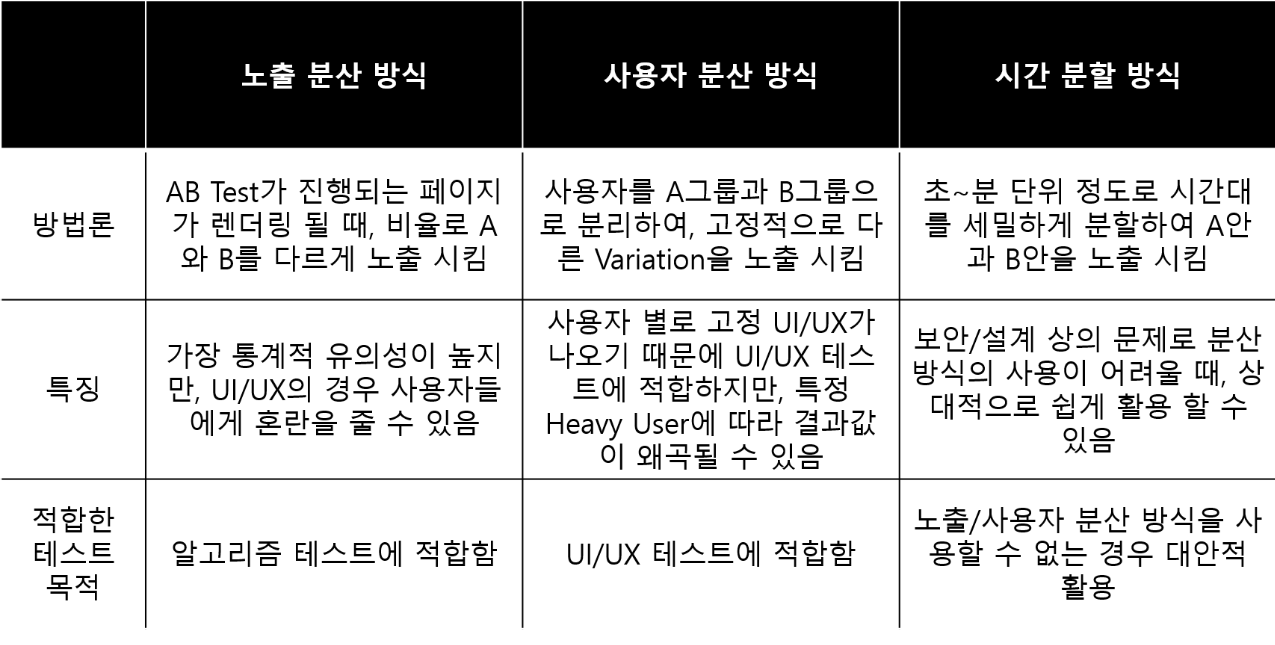
1. 노출 분산 방식 : AB Test가 진행되는 페이지가 렌더링 될 때, 비율로 A와 B를 다르게 노출
2. 사용자 분산 방식 : 사용자를 A그룹과 B그룹으로 분리하여, 고정적으로 다른 Variation을 노출
3. 시간 분할 방식 : 초 ~ 분 단위 정도로 시간대를 세밀하게 분할하여 A안과 B안을 노출
- 진행방법
1. 리서치 (AB Test 진행 전 현재 상태의 성과를 측정)
2. 가설수립
3. A안과 B안 생성 (가설을 기반으로 기존 요소가 담긴 A안과 특정 요소를 변형한 B안을 생성)
4. 테스트 진행
5. 분석 및 의사결정
- 유의사항
1. 무가설
테스트를 통해 검증하고 싶은 가설이 없다면 실험에서 얻을 수 있는 결과는 거의 없습니다.
2. 통제 변수 관리 실패
AB테스트가 실패하는 가장 큰 원인은 통제 변수를 식별하지 못했거나, 통제변수를 잘 관리하지 못하는 것입니다.
가설에서 정의한 독립 변수 외 다른 변수가 종속 변수에 영향을 미쳤다면 그 결과를 활용할 수 없습니다.
3. 단순 평균 비교
종속변수의 변화를 단순 평균과 비교하면 우연에 의한 결과와 실제 효과를 혼동할 수 있습니다.
평균 비교 외에도 분포, 유의수준 등을 종합적으로 고려해서 결과를 해석해야 합니다.
4. 시간 흐름 무시
시간의 흐름에 따라 종속 변수가 어떻게 변화했는지를 보는것도 중요합니다.
5. 엿보기와 조기중지
실험중에 계속해서 p-value의 변화를 살펴보다가 p-value가 0.05이하로 내려가는 시점에 갑자기 실험을 중단하는 경우입니다.
통계적으로는 유의미한 차이가 있는 것으로 보이지만, 사실은 실험자가 인위적으로 만들어낸 결과이므로 서비스에 성장에 크게 도움이 되지 않습니다.
6) 과거에 대한 맹신
AB 테스트에서 유의미한 결과가 나왔다고 해서 그것이 계속해서 유의미하다고 보장할 수는 없습니다. 시장 변화, 계절 변화, 유저 변화 등 다양한 요인에 의해 AB테스트 결과는 얼마든지 달라질 수 있기 떄문입니다.
- 종합 :
1. A/B Test는 두 집단을 임의적으로 나누어야 합니다.
2. 테스트하고자 하는 가설을 명확하게 설정하여 테스트를 진행해야 합니다.
- 참조문서
https://www.ascentkorea.com/ab-test/
https://brunch.co.kr/@digitalnative/19
https://datarian.io/blog/a-b-testing
'데이터분석 > 분석방법론' 카테고리의 다른 글
| [분석방법론] LTV 분석 (1) | 2024.04.28 |
|---|---|
| [분석방법론] 퍼널 분석 (0) | 2024.04.28 |
| [분석방법론] RFM 분석 (0) | 2024.04.23 |
| [분석방법론] 코호트 분석 (0) | 2024.04.23 |